Introduction
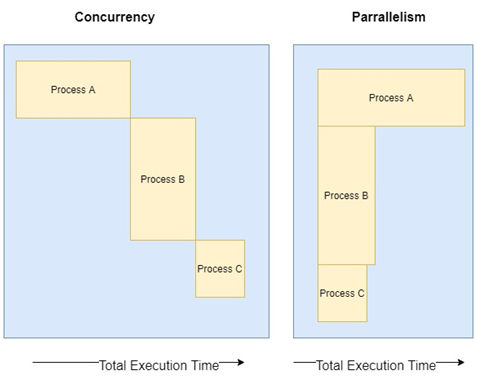
Node.js is renowned for its single-threaded, non-blocking architecture, which is powered by the event loop and ‘libuv‘. However, this has led to a common misconception that Node.js cannot utilize multiple threads for concurrent operations. This article demystifies Node.js’s threading capabilities by introducing Worker Threads and explaining how they can be used for long-running tasks, such as database operations.
The Role of ‘libuv‘ in Node.js
Node.js uses ‘libuv‘, a multi-platform support library with a focus on asynchronous I/O. ‘libuv‘ manages a thread pool, which can handle file system operations, DNS resolution, and other non-JavaScript operations that require asynchronous execution. While JavaScript code runs on a single thread, ‘libuv‘ ensures that blocking operations are offloaded to these worker threads.
Node.js Worker Threads
Introduced in Node.js 10.5.0, Worker Threads provide a way to run JavaScript code in parallel threads. This is particularly useful for CPU-intensive tasks and operations that would otherwise block the event loop.
Example: Using Worker Threads for a Long-Running Database Operation
Let’s explore a practical example of using Worker Threads to handle a long-running database operation without blocking the main thread.
- Initialize the project and install dependencies:
mkdir node-worker-example cd node-worker-example npm init -y npm install express mysql2
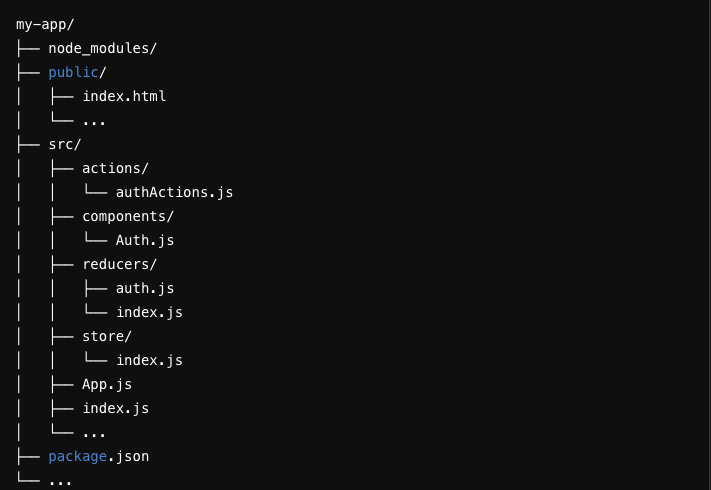
- Create the project structure:

- Worker Thread Implementation:
Create a ‘worker.js‘ file to define the worker:
// worker.js
const { parentPort } = require('worker_threads');
const mysql = require('mysql2/promise');
const dbConfig = {
host: 'localhost',
user: 'db_user',
password: 'db_pw',
database: 'db'
};
async function longRunningDatabaseOperation() {
const connection = await mysql.createConnection(dbConfig);
try {
const [rows] = await connection.execute('SELECT SLEEP(10); SELECT * FROM test_table');
return rows;
} catch (error) {
throw error;
} finally {
await connection.end();
}
}
parentPort.on('message', async (message) => {
if (message === 'start') {
try {
const result = await longRunningDatabaseOperation();
parentPort.postMessage({ status: 'success', data: result });
} catch (error) {
parentPort.postMessage({ status: 'error', error: error.message });
}
}
});
- Main Application Setup:
Create an ‘index.js‘ file for the main application:
// index.js
const express = require('express');
const { Worker } = require('worker_threads');
const app = express();
const port = 3000;
app.get('/non-blocking', (req, res) => {
res.json({ status: 'non blocking finished...' });
}
app.get('/start-operation', (req, res) => {
const worker = new Worker('./worker.js');
worker.on('message', (message) => {
if (message.status === 'success') {
res.json({ status: 'completed', data: message.data });
} else {
res.status(500).json({ status: 'error', error: message.error });
}
});
worker.on('error', (error) => {
res.status(500).json({ status: 'error', error: error.message });
});
worker.on('exit', (code) => {
if (code !== 0) {
console.error(`Worker stopped with exit code ${code}`);
}
});
worker.postMessage('start');
res.json({ status: 'processing' });
});
app.get('/', (req, res) => {
res.send('Hello, world!');
});
app.listen(port, () => {
console.log(`Server running at http://localhost:${port}`);
});
- Running the Project:
- Start the server:
- Test the endpoints:
- Access the normal route: http://localhost:3000/non-blocking
- Start the long-running operation: http://localhost:3000/start-operation
This example demonstrates how to leverage Worker Threads for a long-running database operation, ensuring that other requests continue to be processed efficiently. Happy coding!
Caveats
While Worker Threads in Node.js offer significant advantages for handling CPU-intensive and long-running tasks, they also come with some drawbacks.
- Increased Complexity
- Concurrency Issues: Introducing multiple threads can lead to issues such as race conditions, deadlocks, and other concurrency-related bugs, making the code harder to debug and maintain.
- Communication Overhead: Communicating between the main thread and worker threads requires serialization and deserialization of messages, which can introduce overhead and complexity.
- Performance Considerations
- Thread Creation Overhead: Creating and managing worker threads incurs some overhead, which might negate the performance benefits for small or simple tasks.
- Resource Consumption: Each worker thread consumes additional memory and CPU resources. For tasks that are not CPU-bound or do not benefit significantly from parallel execution, this can lead to inefficiencies.
- Debugging and Profiling
- Complex Debugging: Debugging issues in a multithreaded environment is generally more complex than in a single-threaded one. Tools and techniques for debugging need to account for the parallel execution context.
- Profiling Challenges: Performance profiling in a multithreaded application can be more challenging, as it requires analyzing multiple execution contexts simultaneously.
- Compatibility and Ecosystem
- Module Compatibility: Not all Node.js modules are thread-safe or designed to work in a multithreaded environment. This can limit the choice of modules or require additional effort to ensure compatibility.
- Library Support: While many libraries are compatible with Worker Threads, some may not be, or they may require additional configuration to work correctly in a multithreaded context.
- Development Overhead
- Learning Curve: Developers need to understand the nuances of working with threads, including thread synchronization, message passing, and potential pitfalls of concurrent execution.
- Increased Code Complexity: Managing worker threads and ensuring proper communication and synchronization can increase the overall complexity of the application codebase.
- Use Case Suitability
- Not Always Necessary: For many I/O-bound tasks, Node.js’s non-blocking, asynchronous nature provides sufficient performance without the need for Worker Threads. Using Worker Threads for such tasks may not provide significant benefits and can complicate the architecture unnecessarily.
Conclusion
Node.js’s Worker Threads offer a powerful way to handle CPU-intensive and long-running tasks without blocking the main thread. This capability, coupled with libuv‘s asynchronous I/O operations, debunks the myth that Node.js cannot handle multithreading. By using Worker Threads, developers can build more efficient and responsive applications.
While Worker Threads provide powerful capabilities for handling CPU-intensive and long-running tasks in Node.js, they also introduce complexity and potential performance issues. It is essential to evaluate whether the benefits of using Worker Threads outweigh the drawbacks for your specific use case. For many applications, Node.js’s asynchronous, event-driven model may be sufficient, and Worker Threads should be used judiciously to avoid unnecessary complexity and resource consumption.