
In a project that I was working on, we were discussing using “map-reduce” to process our application data faster and when we were discussing about leveraging current multi processors to process faster , I found there was some confusion about concurrency vs parallelism within the team. So I thought maybe I can explain the difference in a layman’s term so that all can grasp the idea.
Let us first look at what is concurrency
According to Wikipedia
In computer science, concurrency is the ability of different parts or units of a program, algorithm, or problem to be executed out-of-order or in partial order, without affecting the final outcome. This allows for parallel execution of the concurrent units, which can significantly improve overall speed of the execution in multi-processor and multi-core systems. In more technical terms, concurrency refers to the decomposability property of a program, algorithm, or problem into order-independent or partially-ordered components or units.[1]
Quite a mouthful right?
So what about parallelism or parallel computing
Parallel computing is a type of computation in which many calculations or the execution of processes are carried out simultaneously.[1] Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling.[2] As power consumption (and consequently heat generation) by computers has become a concern in recent years,[3] parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.[4]
Again quite a mouthful … So what does this really mean in apples and oranges term?
Single Task – let’s say you go to the grocery store to buy an apple, and an apple only. This means you have a single task to do.
Concurrency – let’s say you go to the same store, but now you want to buy apples, sugar, cream, milk , and flour to make an apple pie. So now you going to do multiple tasks, but you will select each item one by one at a given time.
Parallelism – Let’s say now, in order to make the same apple pie, you go to the store with couple of your friends and you give each one a set of items to buy. Now the items are being bought at the same time so your completion of the buying becomes much faster.
The following picture show how modern CPU would execute a concurrent or a parallel execution
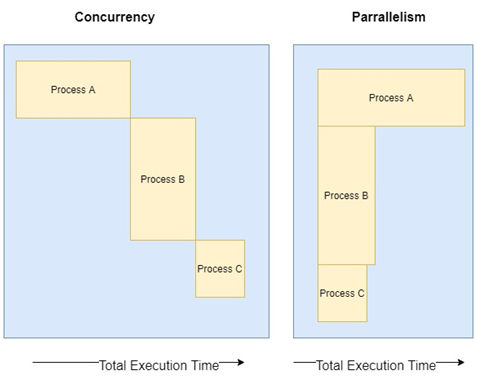
Modern languages support to write applications using concurrency and support them being executed in parallel with multi core systems.
I have created a simple go application which creates go routines with and without channels that shows how concurrent tasks will run in multi core systems using parallelism. You can get the code @
https://github.com/IndikaMaligaspe/go-concurrnecy
Before we dive into code , we need to get an understanding of the difference between threads and Goroutine
| Threads | Goroutine |
| Have own execution stack | Have own execution stac |
| Fixed stack space (around 1 MB) | Variable stack space (starts @2 KB) |
| Managed by OS | Managed by Go runtime |
Let’s look at some code snippets
package main
import (
"fmt"
"github.com/indikamaligaspe/go-concurrnecy/src/movies/channels"
"github.com/indikamaligaspe/go-concurrnecy/src/movies/waitgroups"
)
func main() {
fmt.Println("Starting With WAITGROUPS")
waitgroups.StartWaitGroup()
fmt.Println("Starting With CHANNELS")
channels.StartChannels()
}
Using Channels
func StartChannels() {
wg := &
sync.WaitGroup{}
m := &sync.RWMutex{}
cacheCh := make(chan movies.Movie)
dbCh := make(chan movies.Movie)
for i := 1; i < 10; i++ {
id := rnd.Intn(10) + 1
wg.Add(2)
go func(id int, wg *sync.WaitGroup, m *sync.RWMutex, ch chan<- movies.Movie) {
if movie, ok := queryCahce(id, m); ok {
ch <- movie
}
wg.Done()
}(id, wg, m, cacheCh)
go func(id int, wg *sync.WaitGroup, m *sync.RWMutex, ch chan<- movies.Movie) {
if movie, ok := queryDatabase(id, m); ok {
m.Lock()
chcache[id] = movie
m.Unlock()
ch <- movie
}
wg.Done()
}(id, wg, m, dbCh)
go func(cacheCh, dbCh <-chan movies.Movie) {
select {
case movie := <-cacheCh:
fmt.Println("From Cache ->")
fmt.Println(movie)
<-dbCh
case movie := <-dbCh:
fmt.Println("From Database ->")
fmt.Println(movie)
}
}(cacheCh, dbCh)
time.Sleep(150 * time.Millisecond)
}
wg.Wait()
}
Without channels
func StartWaitGroup() {
wg := &sync.WaitGroup{}
m := &sync.RWMutex{}
for i := 0; i < 10; i++ {
fmt.Printf("Run %v : ", (i + 1))
id := rnd.Intn(10) + 1
wg.Add(2)
go func(id int, wg *sync.WaitGroup, m *sync.RWMutex) {
movie, ok := queryCahce(id, m)
if ok {
fmt.Println("From Cache")
fmt.Println(movie)
}
wg.Done()
}(id, wg, m)
go func(id int, wg *sync.WaitGroup, m *sync.RWMutex) {
movie, ok := queryDatabase(id, m)
if ok {
fmt.Println("From Database")
fmt.Println(movie)
}
wg.Done()
}(id, wg, m)
time.Sleep(150 * time.Millisecond)
}
wg.Wait()
}
When executed we can see that the application runs utilizing all the cores in my notebook
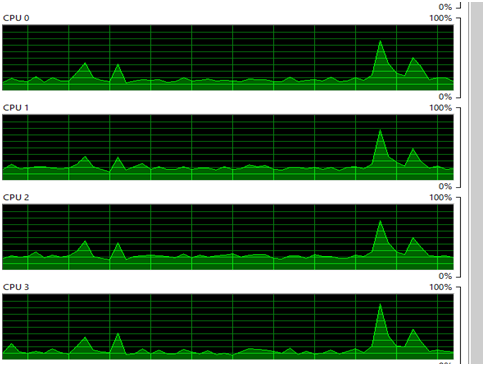
Well , I hope this gave an idea about the difference and how Go handled parallelism with goroutines